GPTとベルトルデータベースPincone

こんにちは、小さなIT会社はりうすの代表の"のすけ"です。
最近のAIの進歩すごいですよね。
深層学習が注目されてから、しばらくは流行っていたけれど。
その後、しばらく落ち着いた感じになって、そのあと出てきたChatGPTの衝撃!
そして、オープンでの世界中の開発の活発化。
大規模言語モデルLLMがものスゴい数でています。
そんな中で、技術界隈で注目されているベクトルデータベースで有名なPinecone
触ってみました。
LLMでのホットなキーワードとして、「記憶力」と「幻覚」があるかと思います。
幻覚 ハルシネーション
幻覚とは、事実とは違うそれっぽい事をAIが答えること。
創造性とも言えるけど、これが酷いとちょっと使いずらい。
人工知能の幻覚(hallucination[注 1]: ハルシネーション)とは、人工知能が学習したデータからは正当化できないはずの回答を堂々とする現象である[3]。例えば、テスラの収益に関する知識がないチャットボットがこの現象に陥ると、もっともらしいと判断したランダムな数字(130.6億ドルのような)を内部的にピックアップして、間違っているにもかかわらずテスラの収益は130.6億ドルだと繰り返すようになる。そしてこのとき、人工知能の内部ではこの数字が自身の創造の産物だということに気付いている兆候がみられない[4]。
Wikipedia
記憶力
Wikipediaに最適な項目がなかったのだけど、ChatGPTを使っている人はわかると思うけれど
記憶力が低いのだよね。
数十行前に定義した会話内容を忘れてしまって、頓珍漢なことを返答してしまう問題。
せっかく序文で、「AIのあなたは学校の先生で、私は生徒です」そのせっていで、話をしてください。
とやっていても。いくつか会話が進むと最初の設定を忘れて返答してしまう。
記憶問題を解決する一つの方法がベクトルデータベース
幻覚については、現在いろいろ研究中のようですが、記憶力についての一つの解決策がベクトルデータベースになります。
そして、それをサービスとして提供しているのがPinecone

今回はこれをOpenAIと絡めて試してみたいと思います
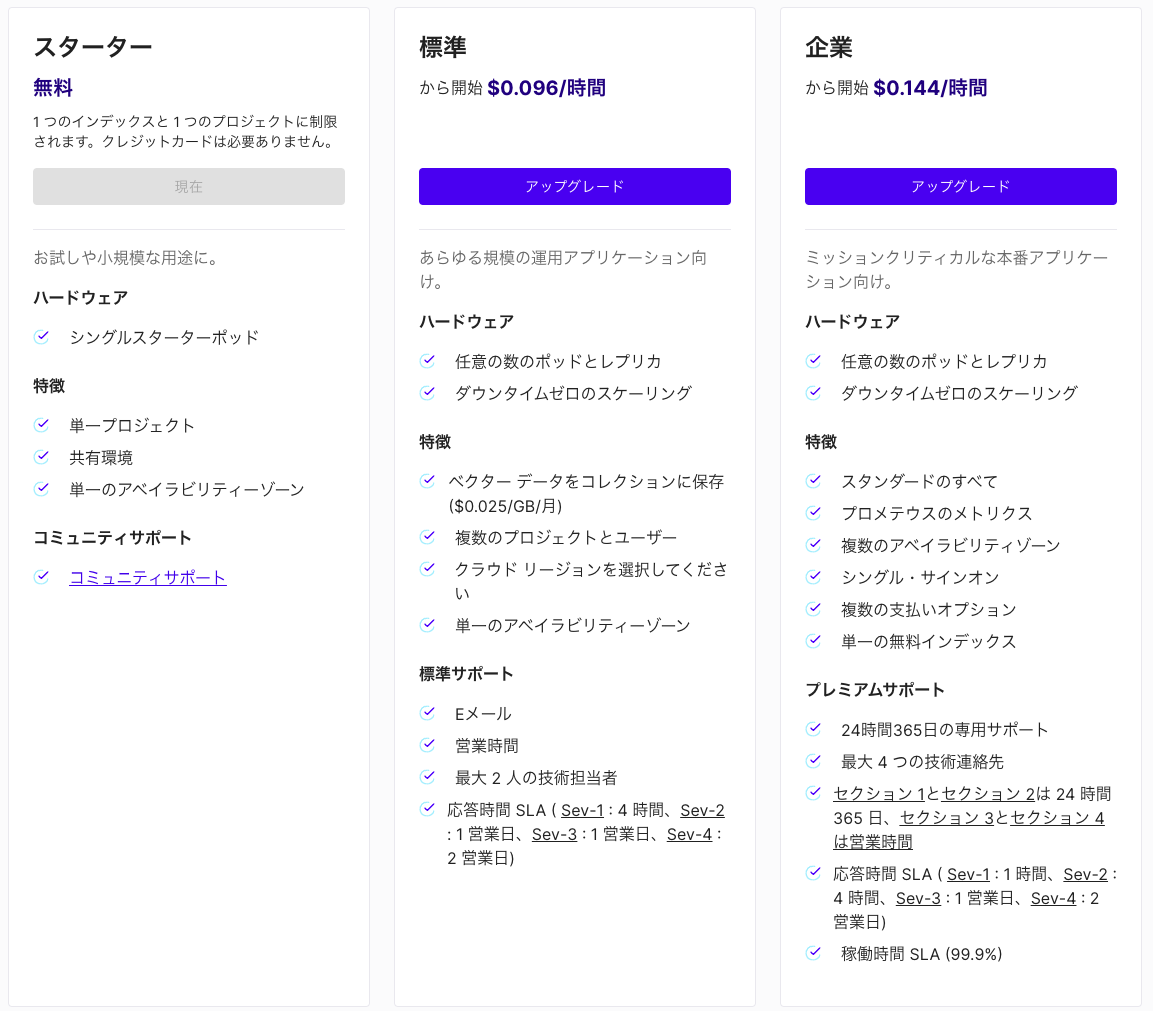
プランは4つ
無料のStarterプラン、標準プラン、企業プラン、エンタープライズプラン。
エンタープライズプランは任意のVPCに入れることができるようで、要問い合わせです。
まずは、無料プランで試しました。
1 つのインデックスと 1 つのプロジェクトに制限されます。クレジットカードは必要ありません。とのこと
無料プランは非アクティブの期間が7日続くとインデックスが削除されます。
パッケージインストール
pip install openai pip install pinecone-client pip install transformers
OpenAI設定
OpenAIの設定をあらかじめしておきます
APIを利用するためには、OpenAIアカウントを作成して
https://platform.openai.com/api-keys
でAPI Keyを作成します
import openai os.environ["OPENAI_API_KEY"] = "xxxxxxxx" openai.api_key = os.environ["OPENAI_API_KEY"]
学習させたデータを読み込み
あらかじめ"datas"というフォルダに読み込ませたいドキュメントを置いておきます
llamaIndexで読み込みます
from llama_index import SimpleDirectoryReader, StorageContext documents = SimpleDirectoryReader("datas").load_data() #ドキュメントのロード
PineconeのIndex設定
APIKeyを設定
import pinecone pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
インデックス作成
# pineconeのインデックスを作成 pinecone.create_index( name="test-index", dimension=1536, metric="dotproduct", # euclidean:ユークリッド距離 cosine:コサイン類似度 dotproduct:内積 pod_type="p1" # starter:starter-plan, s1:1CPU 1GPU 1TPU, p1:1CPU 1GPU, p2:1CPU 2GPU )
こんな感じでPineconeのインデックスができる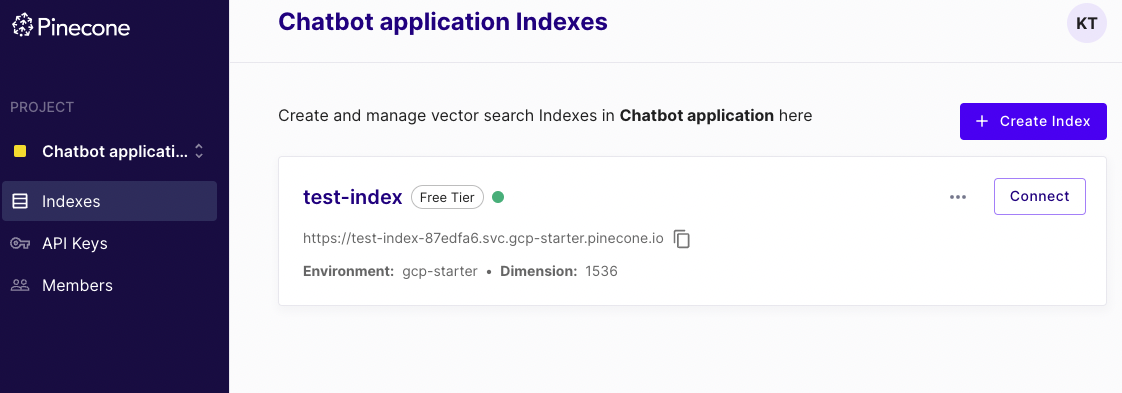
from llama_index import SimpleDirectoryReader, StorageContext, VectorStoreIndex, load_index_from_storage documents = SimpleDirectoryReader("datas").load_data() #ドキュメントのロード
llamaIndexのインデックスを作成
from llama_index.vector_stores.pinecone import PineconeVectorStore pinecone_index = pinecone.Index("test-index") vector_store = PineconeVectorStore(pinecone_index=pinecone_index) strage_context = StorageContext.from_defaults(vector_store=vector_store) # ドキュメントをインデックス index = VectorStoreIndex.from_documents(documents, storage_context=strage_context) # クエリエンジンを作成 query_engine = index.as_query_engine()
質問を入力してテスト!
print(query_engine.query("質問文を入力"))
入力した質問が、あらかじめ読み込んだドキュメントデータに基づいて出力されました。
まとめ
OpenAIのAPIを利用して、ベクトル化したものを
Pineconeを使って類似度を算出
そのデータをLamaIndexから参照して、長期記憶に基づくクエリ(質問)を投げて見た
Metaにもfaissというベクトルデータベースライブラリがありますが,それと同じように利用できた。
今回はドキュメント3つで試したため、
Pineconeとfaissで体感的な速度の違いは感じられなかった。より大きなドキュメントデータを事前に記憶する場合には、サーバーを選べるPineconeの利点がでてくるのだと思う